Поряд з визначенням характеру зв’язку та ефектів впливу факторів на результат важливе значення має оцінка щільності зв’язку, тобто оцінку узгодженості варіації взаємопов’язаних ознак. Якщо вплив х на у значний, то це виявиться в закономірній зміні значень у зі зміною значень х, тобто фактор х своїм впливом формує варіацію у. За відсутності зв’язку варіація у не залежить від варіації х.
Для оцінки щільності зв’язку статистика використовує коефіцієнти з такими властивостями:
за відсутності біль-якого зв’язку значення коефіцієнта наближається до нуля; при функціональному зв’язку – до одиниці;
за наявності кореляційного зв’язку коефіцієнт виражається дробом, який тим за абсолютною величиною тим більший, чим щільніший зв’язок.
Серед мір щільності зв’язку найпоширенішим є коефіцієнт кореляції Пірсона. Позначається цей коефіцієнт символом r. Оскільки сфера його використання обмежується лінійною залежністю, то і в назві фігурує слово „лінійний”. Обчислення лінійного коефіцієнта кореляції ґрунтується на відхиленнях значень взаємозв’язаних ознак х і у від середніх:
.
Він набуває значень у межах ±1, тому характеризує не лише щільність, а й напрямок зв’язку. Додатне значення свідчить про прямий зв’язку, а від’ємне — про зворотній.
Відхилення емпіричних значень у від теоретичних називають залишковими. Вони характеризують вплив на результативну ознаку всіх інших факторів, окрім х. Середній квадрат цих відхилень визначає залишкова дисперсія:
Варіацію у, зумовлену впливом тільки фактора x, вимірює факторна дисперсія:
.
Частка факторної дисперсії у загальній характеризує щільність звязку і називається коефіцієнтом детермінації:
.
Він має такий же зміст, інтерпретацію та цифрові межі, як і h2.
Щільність зв’язку оцінюється також індексом кореляції , проте інтерпретується лише R2 .
Перевірка істотності зв’язку здійснюється таким же чином, як і в моделі аналітичного групування, шляхом порівняння R2 і . Відмінності стосуються лише визначення k1 = т ? 1 та k2 = п ? т у яких m — число параметрів рівняння регресії, а п ? кількість спостережень. Гіпотеза, що перевіряється, формулюється як нульова:
Н0: R2 = 0 або Н0: ?2 = 0 .
Перевірка істотності зв’язку в обох моделях може здійснюватись також за F ? критерієм Фішера, який функціонально зв’язаний з R2 та h2 так:
,
або ,
тому процедура перевірки та висновки ідентичні.
7.4. Рангова кореляція Спірмена та Кендала
В деяких випадках ми можемо зіткнутися з такими якостями, які не піддаються вираженню числом одиниць.
Ці обставини заставляють застосовувати “не параметричні методи”, які дають змогу вимірювати інтенсивність зв’язків між кількісними ознаками, форма розподілу яких відрізняється від нормального і між якісними ознаками. В основу не параметричних методів покладено принцип нумерації варіант ряду. Взаємозв’язок між ознаками, які можна зранжувати, передусім на основі бальних оцінок, вимірюється методами рангової кореляції. Кожній одиниці сукупності присвоюється порядковий номер в ряді, який буде впорядковано за рівнем ознаки. Таким чином, ряд значень ознаки впорядковується, а номер кожного окремого значення називатиметься її рангом.
Ранжування проводиться за кожною ознакою окремо: перший ранг надається найменшому значенню ознаки, останній — найбільшому або навпаки. Кількість рангів дорівнює обсягу сукупності. Очевидно, зі збільшенням обсягу сукупності ступінь „розпізнаваності” елементів зменшується. З огляду на те, що рангова кореляція не потребує додержання будь-яких математичних передумов щодо розподілу ознак, зокрема вимоги нормальності розподілу, рангові оцінки щільності зв’язку доцільно використовувати для сукупностей невеликого обсягу.
Ранги, надані елементам сукупності за ознаками х і у, позначають відповідно Rx та Ry. Залежно від ступеня зв’язку між ознаками певним чином співвідносяться й ранги. При прямому функціональному зв’язку Rx = Ry тобто відхилення між рангами d = Rx ? Ry = 0, отже, і сума квадратів відхилень . При зворотному функціональному зв’язку , де п — число рангів. Якщо зв’язок між ознаками відсутній, являє собою середню арифметичну цих крайніх значень:
Обчислення коефіцієнта кореляції Спірмена ґрунтується на вивченні різниці рангів значень факторної та результативної ознаки:
,
де di ? відхилення рангів факторної та результативної ознак (різниця), n — кількість рангів. і одночасно оцінює щільність зв’язку та його напрямок.
Кендал запропонував так знаходити коефіцієнт кореляції:
,
де S – сума балів при умові, що балом +1 оцінюється пара рангів, які мають за обома ознаками однаковий порядок, а балом –1 – пара рангів з оберненим порядком.
1) впорядковуємо ряд значень ознаки х за зростанням і вказуємо ранги ознаки у відповідно;
2) обчислюємо бали для всіх рангів за ознакою у. Для цього визначаємо, скільки рангів, які знаходяться перед та після даного, перевищують його. Перше число записуємо зі знаком “?”, друге – зі знаком “+”.
3) знаходимо суму балів за всіма рангами;
4) обчислюємо значення коефіцієнта .
Зауваження: якщо значення ознаки у однакові, то однаковими повинні бути і їх ранги. Для цього з рангів, які б мали бути присвоєнні різним значенням, знаходять середній і присвоюють кожному з рівних значень. Наприклад ( таб. 7.4.1):
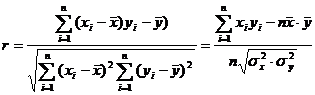 .
.
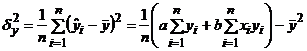 .
. .
. ,
,